
Tesseract - один из самых мощных механизмов OCR с открытым исходным кодом, доступных сегодня. OCR обозначает оптическое распознавание символов. Это процесс извлечения текстов из изображений. Например, рассмотрим следующее изображение, в котором есть текст, который должен быть извлечен:
Выход из OCR-модуля, как только обработка будет выполнена, будет примерно такой:
открыто Доступ кнопка
Вот как работает OCR.
Он полезен во многих приложениях, таких как распознавание номерных знаков автомобиля, преобразование отсканированных копий документов в формат слова, автоматическое извлечение деталей из квитанций и т. Д. Он также является первым шагом во многих задачах обработки естественного языка. В этом уроке мы рассмотрим, как быстро установить и настроить Tesseract, imagemagick и как использовать их для получения наилучших результатов при предварительной обработке изображений.
Предварительная обработка изображения является важной частью выполнения OCR с помощью Tesseract. Это гарантирует высокую точность извлеченного текста и уменьшает погрешность. Мы рассмотрим некоторые основные операции, которые будут выполняться на изображении, используя его. Imagemagick - это инструмент командной строки для обработки изображений, который помогает нам выполнять такие операции, как обрезка, изменение размера, изменение цветовых схем и т. Д.
1 Установите Tesseract
Достаточно просто установить tesseract, запустить следующие команды:
sudo apt update sudo apt install tesseract-ocr
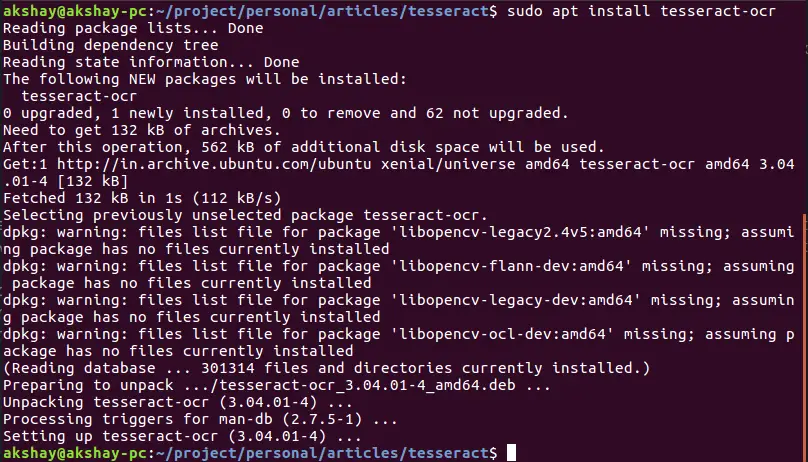
Это устанавливает двигатель Tesseract. На рисунке ниже показан вывод, когда он установлен правильно:
Следующее, что нужно сделать, это установить языковые пакеты. Tesseract очень надежный и может извлекать более 100 различных языков при условии загрузки языковых пакетов. Вы можете загрузить определенный языковой пакет с помощью общей команды ниже:
sudo apt-get install tesseract-ocr- [lang]
В приведенной выше команде замените «[lang]» на язык, который вы хотите загрузить. Ниже приведены примеры английского и французского языков:
sudo apt-get install tesseract-ocr-eng sudo apt-get install tesseract-ocr-fra
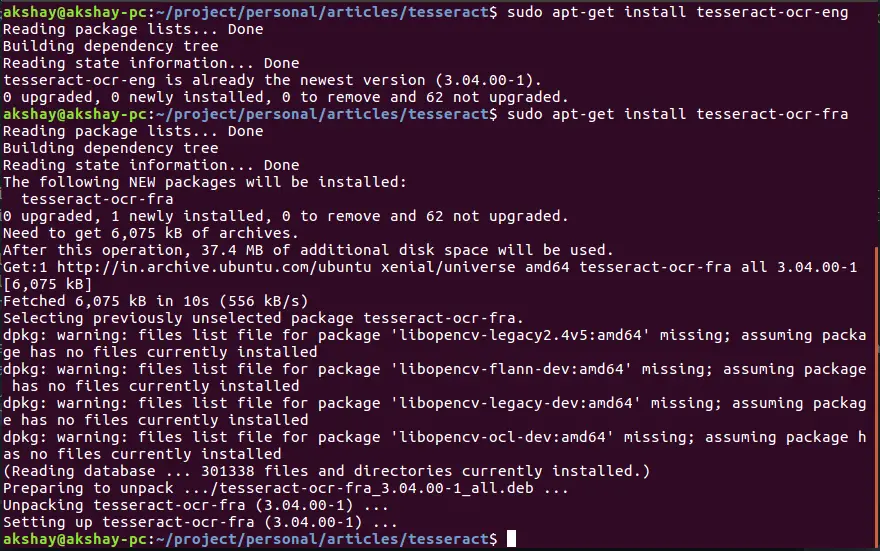
Обычно tesseract поставляется с английским пакетом по умолчанию. На приведенном ниже рисунке показано, что английский уже установлен, а французский должен быть загружен и установлен:
Кроме того, если вы хотите, чтобы все языковые пакеты были загружены, вы можете запустить следующую команду:
sudo apt-get install tesseract-ocr-all
Это завершает установку Tesseract.
2 Установите Imagemagick Выполните следующую команду для установки imagemagick
sudo apt install imagemagick
Этот инструмент используется из командной строки с помощью команды convert . Чтобы проверить правильность установки, выполните следующую команду, и результат должен быть похож на изображение ниже:
конвертировать -h
3 Использование Tesseract
Tesseract способен принимать изображения из разных форматов, таких как jpg, png, tiff и т. Д. И извлекать из него текст. В этом разделе основное внимание уделяется запуску tesseract и в следующем разделе мы увидим, как мы можем повысить точность. Вот несколько основных команд для запуска tesseract:
Чтобы получить вывод в терминале, запустите общую команду с контуром изображения
tesseract [image_path] stdout
Чтобы сохранить вывод OCR в файл, выполните следующую общую команду:
tesseract [image_path] [имя_файла]
Следуя двум изображениям, покажите используемое изображение и результат выполнения приведенных выше команд на этом изображении

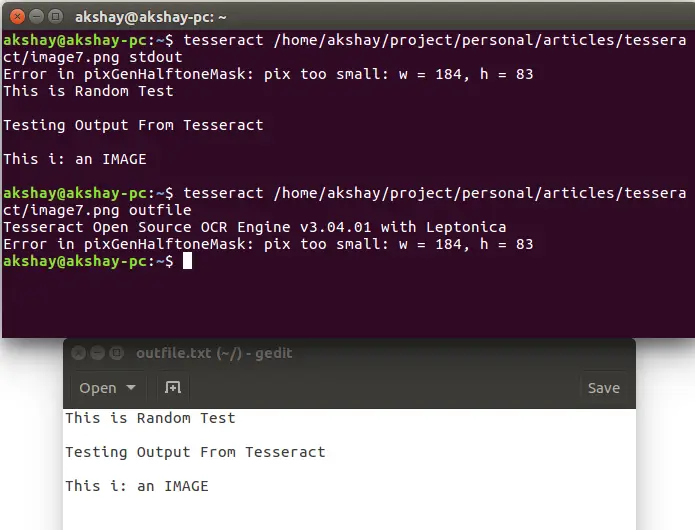
Как вы можете заметить, запуск второй команды привел к созданию файла с именем «outfile.txt», в котором можно найти вывод.
4 Предварительная обработка изображения
Из предыдущего вывода вы могли заметить, что на выходе есть ошибка, а также ошибка, указывающая, что размер пикселей невелик. Это один из недостатков Tesseract, он ожидает, что вы получите обработанное изображение, на которое он может выполнять OCR. В этом разделе мы рассмотрим некоторые из тактик, которые вы можете использовать с помощью imagemagick для улучшения качества изображения и, таким образом, повышения точности вывода.
4.1 изменение размера
Изменение размера является одним из наиболее полезных приемов для повышения точности распознавания. Это связано с тем, что большинство изображений времени имеют очень маленький размер шрифта, который Tesseract не может быть правильно прочитан. Вы можете изменить размер изображения, используя следующую команду. Процентная сумма указывает предел изменения размера. Поскольку мы хотим увеличить размер, нам нужно дать значение больше 100. Здесь мы дали значение 150% (используйте метод проб и ошибок, чтобы определить идеальное изменение размера% для вашего варианта использования).
convert -resize 150% [input_file_path] [output_file_path]
в приведенной выше команде замените путь [input_file_path] на путь изображения, размер которого должен быть изменен, а [output_file_path] - на путь изображения, в котором должен храниться выход. Следующим изображением является вывод, когда я запускал команду: convert -resize 150% image7.png image7_resize.png
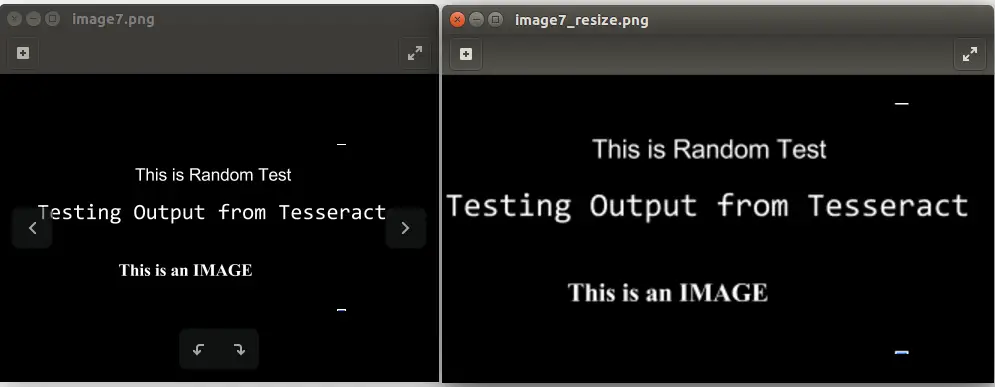
4.2. Использование изображений в оттенках серого
Если у вас есть цветное изображение, рекомендуется сначала преобразовать его в оттенки серого. Существует хороший шанс, что этого достаточно, чтобы получить точность OCR, которую вы хотите. В противном случае для дальнейшей обработки вы можете использовать изображения в оттенках серого для бинаризации изображения. Используйте следующую команду для преобразования вашего изображения, чтобы преобразовать его в оттенки серого
convert [input_file_path] -тип Grayscale [output_file_path]
На следующем рисунке показан вывод для запуска команды convert image6_resize.png -type Grayscale image6_gray.png
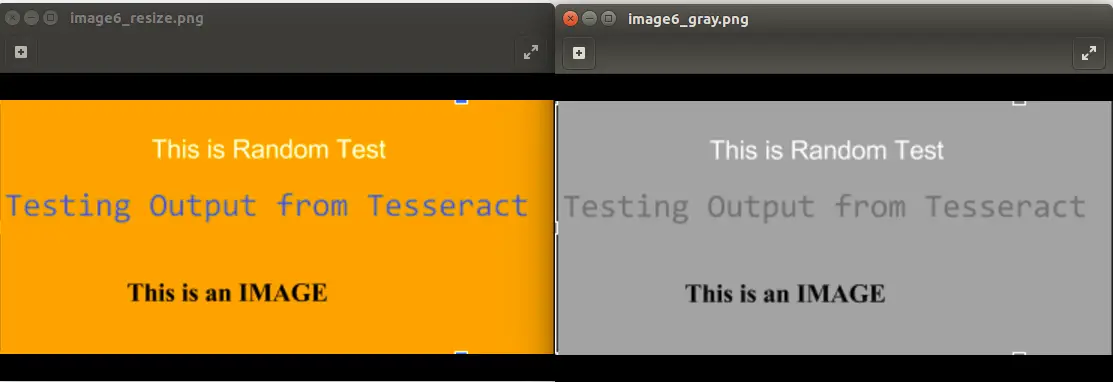
4.3. Бинаризация изображения
Бинаризация или пороговое значение включает в себя преобразование изображения в значения только черного и белого. Каждый пиксель на этом изображении имеет только одно из двух значений: черный или белый. Это значительно снижает сложность изображений. Если у вас есть изображения с шумом или изображениями с тенью или много текста, вы можете использовать этот метод предварительной обработки. Чтобы разбить это изображение на два, убедитесь, что у вас сначала есть изображение в градациях серого, а затем используйте следующую команду:
convert [input_file_path] -пороговый 55% [output_file_path]
Порог% можно варьировать, чтобы получить наилучший результат для вашего варианта использования. На следующем рисунке показан пример. Важно отметить, что для имеющегося изображения бинаризация не является лучшим вариантом, так как она теряет некоторые данные.
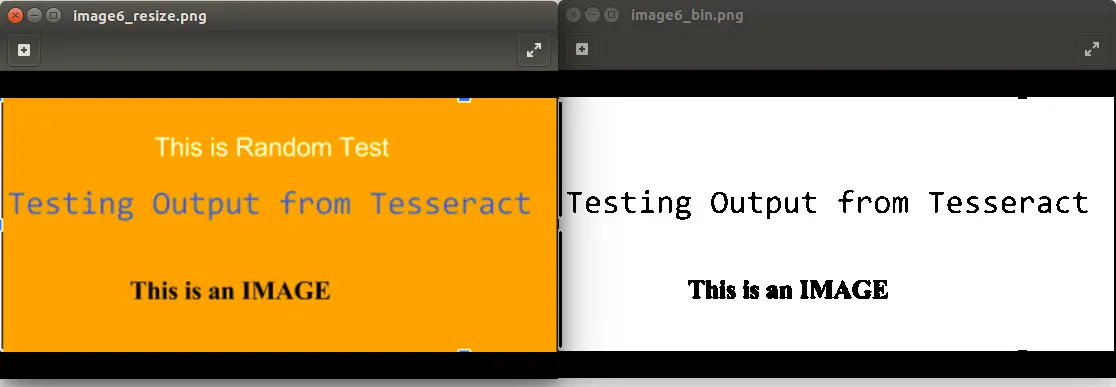
Перед применением любых или всех описанных выше методов предварительной обработки следует иметь в виду следующие моменты:
- В зависимости от варианта использования полезно использовать комбинацию шагов предварительной обработки.
- когда шаг предварительной обработки приводит к снижению точности, его следует игнорировать с этапа предварительной обработки.
- Проценты при изменении размера или пороговых значениях варьируются от изображения к изображению, и поэтому необходимо применять метод проб и ошибок, чтобы получить наилучшее возможное процентное значение, чтобы обеспечить максимальную точность при запуске Tesseract
После того, как вы завершили предварительную обработку, запустите Tesseract с обработанным изображением, чтобы проверить точность. Tesseract очень мощный, но имеет некоторые ограничения, когда речь заходит о типе изображения, которое задается как вход. Надеюсь, вы нашли этот учебник полезным.
Комментариев нет:
Отправить комментарий